Fidêncio, Aline Xavier; Grün, Felix; Klaes, Christian; Iossifidis, Ioannis Error-Related Potential Driven Reinforcement Learning for Adaptive Brain-Computer Interfaces Artikel In: Arxiv, 2025. Abstract | Links | BibTeX | Schlagwörter: BCI, Computer Science - Human-Computer Interaction, Computer Science - Machine Learning, EEG, Quantitative Biology - Neurons and Cognition, Reinforcement learning Grün, Felix; Iossifidis, Ioannis Controversial Opinions on Model Based and Model Free Reinforcement Learning in the Brain Proceedings Article In: BCCN Bernstein Network Computational Networkvphantom, 2024. Abstract | Links | BibTeX | Schlagwörter: Machine Learning, Reinforcement learning Grün, Felix; Iossifidis, Ioannis Investigation of the Interplay of Model-Based and Model-Free Learning Using Reinforcement Learning Proceedings Article In: BC23 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022, BCCN Bernstein Network Computational Network, 2023. Abstract | BibTeX | Schlagwörter: Machine Learning, Reinforcement learning Grün, Felix; Iossifidis, Ioannis Exploring Distribution Parameterizations for Distributional Continuous Control Proceedings Article In: BC22 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022, BCCN Bernstein Network Computational Network, 2022. Links | BibTeX | Schlagwörter: Machine Learning, Reinforcement learning Fidencio, Aline Xavier; Klaes, Christian; Iossifidis, Ioannis Error-Related Potentials in Reinforcement Learning-Based Brain-Machine Interfaces Artikel In: Frontiers in Human Neuroscience, Bd. 16, 2022. Abstract | Links | BibTeX | Schlagwörter: BCI, EEG, error-related potentials, Machine Learning, Reinforcement learning Grün, Felix; Glasmachers, Tobias; Iossifidis, Ioannis Off-Policy Continuous Control Using Distributional Reinforcement Learning Proceedings Article In: Bernstein Conference, 2021. Links | BibTeX | Schlagwörter: Machine Learning, Reinforcement learning Fidencio, Aline Xavier; Glasmachers, Tobias; Klaes, Christian; Iossifidis, Ioannis Beyond Error Correction: Integration of Error-Related Potentials into Brain-Computer Interfaces for Improved Performance Proceedings Article In: Bernstein Conference, 2021. Links | BibTeX | Schlagwörter: BCI, error-related potentials, Machine Learning, Reinforcement learning Grün, Felix; Glasmachers, Tobias; Iossifidis, Ioannis Off-Policy Continuous Control Using Distributional Reinforcement Learning Proceedings Article In: BC21 : Computational Neuroscience & Neurotechnology Bernstein Conference 2021, BCCN Bernstein Network Computational Network, 2021. Links | BibTeX | Schlagwörter: Machine Learning, Reinforcement learning Fidencio, Aline Xavier; Glasmachers, Tobias; Naro, Daniele Application of Reinforcement Learning to a Mining System Proceedings Article In: 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), S. 000111–000118, 2021. Abstract | Links | BibTeX | Schlagwörter: Control Applications, Industrial Application, Machine Learning, Machine learning algorithms, Mining Industry, Reinforcement learning2025
@article{fidencioErrorrelatedPotentialDriven2025,
title = {Error-Related Potential Driven Reinforcement Learning for Adaptive Brain-Computer Interfaces},
author = {Aline Xavier Fidêncio and Felix Grün and Christian Klaes and Ioannis Iossifidis},
url = {http://arxiv.org/abs/2502.18594},
doi = {10.48550/arXiv.2502.18594},
year = {2025},
date = {2025-02-25},
urldate = {2025-02-25},
journal = {Arxiv},
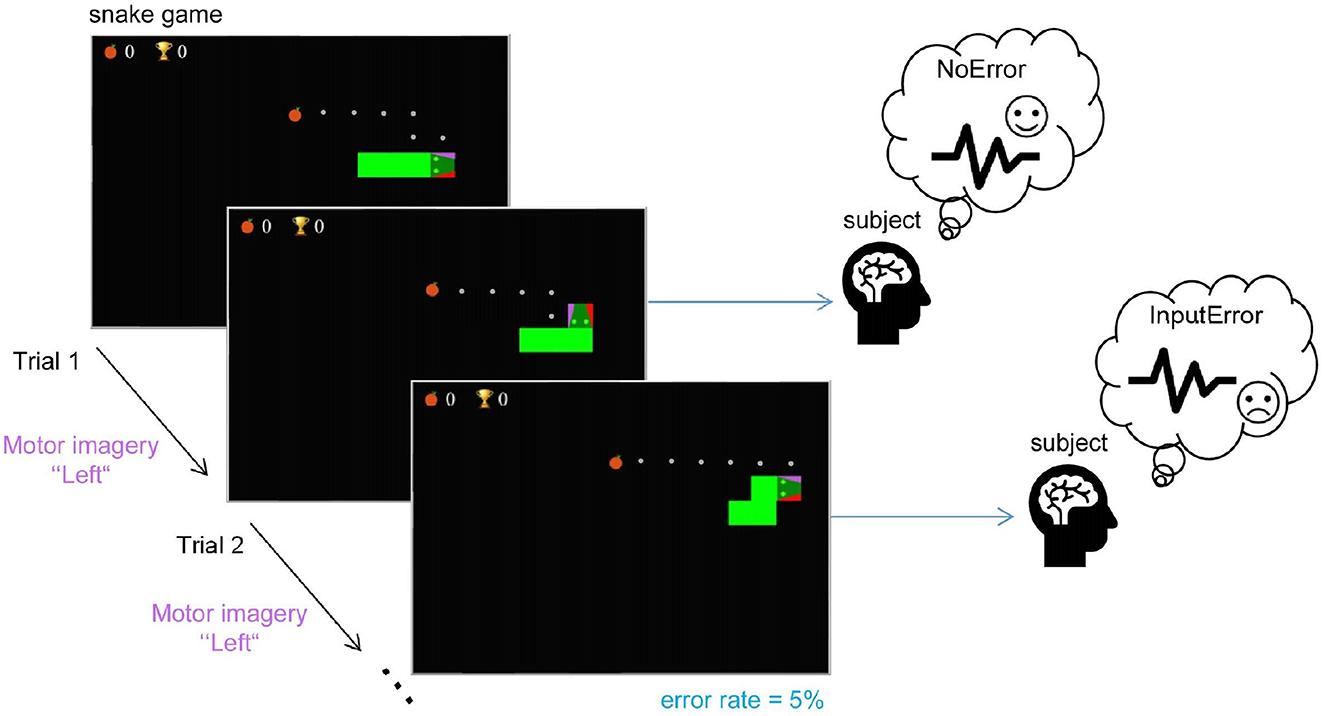
abstract = {Brain-computer interfaces (BCIs) provide alternative communication methods for individuals with motor disabilities by allowing control and interaction with external devices. Non-invasive BCIs, especially those using electroencephalography (EEG), are practical and safe for various applications. However, their performance is often hindered by EEG non-stationarities, caused by changing mental states or device characteristics like electrode impedance. This challenge has spurred research into adaptive BCIs that can handle such variations. In recent years, interest has grown in using error-related potentials (ErrPs) to enhance BCI performance. ErrPs, neural responses to errors, can be detected non-invasively and have been integrated into different BCI paradigms to improve performance through error correction or adaptation. This research introduces a novel adaptive ErrP-based BCI approach using reinforcement learning (RL). We demonstrate the feasibility of an RL-driven adaptive framework incorporating ErrPs and motor imagery. Utilizing two RL agents, the framework adapts dynamically to EEG non-stationarities. Validation was conducted using a publicly available motor imagery dataset and a fast-paced game designed to boost user engagement. Results show the framework's promise, with RL agents learning control policies from user interactions and achieving robust performance across datasets. However, a critical insight from the game-based protocol revealed that motor imagery in a high-speed interaction paradigm was largely ineffective for participants, highlighting task design limitations in real-time BCI applications. These findings underscore the potential of RL for adaptive BCIs while pointing out practical constraints related to task complexity and user responsiveness.},
keywords = {BCI, Computer Science - Human-Computer Interaction, Computer Science - Machine Learning, EEG, Quantitative Biology - Neurons and Cognition, Reinforcement learning},
pubstate = {published},
tppubtype = {article}
}
2024
@inproceedings{ControversialOpinionsModel2024,
title = {Controversial Opinions on Model Based and Model Free Reinforcement Learning in the Brain},
author = {Felix Grün and Ioannis Iossifidis},
url = {https://abstracts.g-node.org/conference/BC24/abstracts#/uuid/18e92e07-e4b1-43af-b2ac-ea282f4e81e7},
year = {2024},
date = {2024-09-18},
urldate = {2024-09-24},
publisher = {BCCN Bernstein Network Computational Networkvphantom},
abstract = {Dopaminergic Reward Prediction Errors (RPEs) are a key motivation and inspiration for model free, temporal difference reinforcement learning methods. Originally, the correlation of RPEs with model free temporal difference errors was seen as a strong indicator for model free reinforcement learning in brains. The standard view was that model free learning is the norm and more computationally expensive model based decision-making is only used when it leads to outcomes that are good enough to justify the additional effort. Nowadays, the landscape of opinions, models and experimental evidence, both electrophysiological and behavioral, paints a more complex picture, including but not limited to mechanisms of arbitration between the two systems. Model based learning or hybrid models better capture experimental behavioral data, and model based signatures are found in RPEs that were previously thought to be model free or hybrid [1]. The evidence for clearly model free learning is scarce [2]. On the other hand, multiple approaches show how model based behavior and RPEs can be produced with fundamentally model free reinforcement learning methods [3, 4, 5]. We point out findings that seem to contradict each other, others that complement each other, speculate which ideas are compatible with each other and give our opinions on ways forward, towards understanding if and how model based and model free learning from rewards coexist and interact in the brain.},
keywords = {Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
2023
@inproceedings{grunInvestigationInterplayModelBased2023,
title = {Investigation of the Interplay of Model-Based and Model-Free Learning Using Reinforcement Learning},
author = {Felix Grün and Ioannis Iossifidis},
year = {2023},
date = {2023-09-15},
urldate = {2023-09-15},
booktitle = {BC23 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022},
publisher = {BCCN Bernstein Network Computational Network},
abstract = {The reward prediction error hypothesis of dopamine in the brain states that activity of dopaminergic neurons in certain brain regions correlates with the reward prediction error that corresponds to the temporal difference error, often used as a learning signal in model free reinforcement learning (RL). This suggests that some form of reinforcement learning is used in animal and human brains when learning a task. On the other hand, it is clear that humans are capable of building an internal model of a task, or environment, and using it for planning, especially in sequential tasks. In RL, these two learning approaches, model-driven and reward-driven, are known as model based and model-free RL approaches. Both systems were previously thought to exist in parallel, with some higher process choosing which to use. A decade ago, research suggested both could be used concurrently, with some subject-specific weight assigned to each [1]. Still, the prevalent belief appeared to be that model-free learning is the default mechanism used, replaced or assisted by model-based planning only when the task demands it, i.e. higher rewards justify the additional cognitive effort. Recently, Feher da Silva et al. [2] questioned this belief, presenting data and analyses that indicate model-based learning may be used on its own and can even be computationally more efficient. We take a RL perspective, consider different ways to combine model-based and model-free approaches for modeling and for performance, and discuss how to further study this interplay in human behavioral experiments.},
keywords = {Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
2022
@inproceedings{grunExploringDistributionParameterizations2022,
title = {Exploring Distribution Parameterizations for Distributional Continuous Control},
author = {Felix Grün and Ioannis Iossifidis},
doi = {10.12751/nncn.bc2022.112},
year = {2022},
date = {2022-09-15},
urldate = {2022-09-15},
booktitle = {BC22 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022},
publisher = {BCCN Bernstein Network Computational Network},
keywords = {Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
@article{xavierfidencioErrorrelated,
title = {Error-Related Potentials in Reinforcement Learning-Based Brain-Machine Interfaces},
author = {Aline Xavier Fidencio and Christian Klaes and Ioannis Iossifidis},
url = {https://www.frontiersin.org/article/10.3389/fnhum.2022.806517},
doi = {https://doi.org/10.3389/fnhum.2022.806517},
year = {2022},
date = {2022-06-24},
urldate = {2022-06-24},
journal = {Frontiers in Human Neuroscience},
volume = {16},
abstract = {The human brain has been an object of extensive investigation in different fields. While several studies have focused on understanding the neural correlates of error processing, advances in brain-machine interface systems using non-invasive techniques further enabled the use of the measured signals in different applications. The possibility of detecting these error-related potentials (ErrPs) under different experimental setups on a single-trial basis has further increased interest in their integration in closed-loop settings to improve system performance, for example, by performing error correction. Fewer works have, however, aimed at reducing future mistakes or learning. We present a review focused on the current literature using non-invasive systems that have combined the ErrPs information specifically in a reinforcement learning framework to go beyond error correction and have used these signals for learning.},
keywords = {BCI, EEG, error-related potentials, Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {article}
}
2021
@inproceedings{grunOffPolicyContinuousControl2021b,
title = {Off-Policy Continuous Control Using Distributional Reinforcement Learning},
author = {Felix Grün and Tobias Glasmachers and Ioannis Iossifidis},
doi = {10.12751/nncn.bc2021.p001},
year = {2021},
date = {2021-10-01},
urldate = {2021-10-01},
publisher = {Bernstein Conference},
keywords = {Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
@inproceedings{xavierfidencioErrorCorrectionIntegration2021b,
title = {Beyond Error Correction: Integration of Error-Related Potentials into Brain-Computer Interfaces for Improved Performance},
author = {Aline Xavier Fidencio and Tobias Glasmachers and Christian Klaes and Ioannis Iossifidis},
doi = {10.12751/nncn.bc2021.p163},
year = {2021},
date = {2021-10-01},
urldate = {2021-10-01},
publisher = {Bernstein Conference},
keywords = {BCI, error-related potentials, Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
@inproceedings{grunOffPolicyContinuousControl2021,
title = {Off-Policy Continuous Control Using Distributional Reinforcement Learning},
author = {Felix Grün and Tobias Glasmachers and Ioannis Iossifidis},
doi = {10.12751/nncn.bc2021.p001},
year = {2021},
date = {2021-09-15},
urldate = {2021-09-15},
booktitle = {BC21 : Computational Neuroscience & Neurotechnology Bernstein Conference 2021},
publisher = {BCCN Bernstein Network Computational Network},
keywords = {Machine Learning, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
@inproceedings{fidencioApplicationReinforcementLearning2021,
title = {Application of Reinforcement Learning to a Mining System},
author = {Aline Xavier Fidencio and Tobias Glasmachers and Daniele Naro},
doi = {10.1109/SAMI50585.2021.9378663},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
booktitle = {2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI)},
pages = {000111--000118},
abstract = {Automation techniques have been widely applied in different industry segments, among others, to increase both productivity and safety. In the mining industry, with the usage of such systems, the operator can be removed from hazardous environments without compromising task execution and it is possible to achieve more efficient and standardized operation. In this work a study case on the application of machine learning algorithms to a mining system example is presented, in which reinforcement learning algorithms were used to solve a control problem. As an example, a machine chain consisting of a Bucket Wheel Excavator, a Belt Wagon and a Hopper Car was used. This system has two material transfer points that need to remain aligned during operation in order to allow continuous material flow. To keep the alignment, the controller makes use of seven degrees of freedom given by slewing, luffing and crawler drives. Experimental tests were done in a simulated environment with two state-of-the-art algorithms, namely Proximal Policy Optimization (PPO) and Soft Actor-Critic (SAC). The trained agents were evaluated in terms of episode return and length, as well as alignment quality and action values used. Results show that, for the given task, the PPO agent performs quantitatively and qualitatively better than the SAC agent. However, none of the agents were able to completely solve the proposed testing task.},
keywords = {Control Applications, Industrial Application, Machine Learning, Machine learning algorithms, Mining Industry, Reinforcement learning},
pubstate = {published},
tppubtype = {inproceedings}
}
Error-Related Potential Driven Reinforcement Learning for Adaptive Brain-Computer Interfaces Artikel In: Arxiv, 2025. Controversial Opinions on Model Based and Model Free Reinforcement Learning in the Brain Proceedings Article In: BCCN Bernstein Network Computational Networkvphantom, 2024. Investigation of the Interplay of Model-Based and Model-Free Learning Using Reinforcement Learning Proceedings Article In: BC23 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022, BCCN Bernstein Network Computational Network, 2023. Exploring Distribution Parameterizations for Distributional Continuous Control Proceedings Article In: BC22 : Computational Neuroscience & Neurotechnology Bernstein Conference 2022, BCCN Bernstein Network Computational Network, 2022. Error-Related Potentials in Reinforcement Learning-Based Brain-Machine Interfaces Artikel In: Frontiers in Human Neuroscience, Bd. 16, 2022. Off-Policy Continuous Control Using Distributional Reinforcement Learning Proceedings Article In: Bernstein Conference, 2021. Beyond Error Correction: Integration of Error-Related Potentials into Brain-Computer Interfaces for Improved Performance Proceedings Article In: Bernstein Conference, 2021. Off-Policy Continuous Control Using Distributional Reinforcement Learning Proceedings Article In: BC21 : Computational Neuroscience & Neurotechnology Bernstein Conference 2021, BCCN Bernstein Network Computational Network, 2021. Application of Reinforcement Learning to a Mining System Proceedings Article In: 2021 IEEE 19th World Symposium on Applied Machine Intelligence and Informatics (SAMI), S. 000111–000118, 2021.2025
2024
2023
2022
2021