
Lehrgebiet: Theoretische Informatik und künstliche Intelligenz
Büro: 01.214
Labor: 04.105
Telefon: +49 208 88254-806
E-Mail:
🛜 http://lab.iossifidis.net

Ioannis Iossifidis studierte Physik (Schwerpunkt: theoretische Teilchenphysik) an der Universität Dortmund und promovierte 2006 an der Fakultät für Physik und Astronomie der Ruhr-Universität Bochum.
Am Institut für Neuroinformatik leitete Prof. Dr. Iossifidis die Arbeitsgruppe Autonome Robotik und nahm mit seiner Forschungsgruppe erfolgreich an zahlreichen, vom BmBF und der EU, geförderten Forschungsprojekten aus dem Bereich der künstlichen Intelligenz teil. Seit dem 1. Oktober 2010 arbeitet er an der HRW am Institut Informatik und hält den Lehrstuhl für Theoretische Informatik – Künstliche Intelligenz.
Prof. Dr. Ioannis Iossifidis entwickelt seit über 20 Jahren biologisch inspirierte anthropomorphe, autonome Robotersysteme, die zugleich Teil und Ergebnis seiner Forschung im Bereich der rechnergestützten Neurowissenschaften sind. In diesem Rahmen entwickelte er Modelle zur Informationsverarbeitung im menschlichen Gehirn und wendete diese auf technische Systeme an.
Ausgewiesene Schwerpunkte seiner wissenschaftlichen Arbeit der letzten Jahre sind die Modellierung menschlicher Armbewegungen, der Entwurf von sogenannten «Simulierten Realitäten» zur Simulation und Evaluation der Interaktionen zwischen Mensch, Maschine und Umwelt sowie die Entwicklung von kortikalen exoprothetischen Komponenten. Entwicklung der Theorie und Anwendung von Algorithmen des maschinellen Lernens auf Basis tiefer neuronaler Architekturen bilden das Querschnittsthema seiner Forschung.
Ioannis Iossifidis’ Forschung wurde u.a. mit Fördermitteln im Rahmen großer Förderprojekte des BmBF (NEUROS, MORPHA, LOKI, DESIRE, Bernstein Fokus: Neuronale Grundlagen des Lernens etc.), der DFG («Motor‐parietal cortical neuroprosthesis with somatosensory feedback for restoring hand and arm functions in tetraplegic patients») und der EU (Neural Dynamics – EU (STREP), EUCogII, EUCogIII ) honoriert und gehört zu den Gewinnern der Leitmarktwettbewerbe Gesundheit.NRW und IKT.NRW 2019.
ARBEITS- UND FORSCHUNGSSCHWERPUNKTE
- Computational Neuroscience
- Brain Computer Interfaces
- Entwicklung kortikaler exoprothetischer Komponenten
- Theorie neuronaler Netze
- Modellierung menschlicher Armbewegungen
- Simulierte Realität
WISSENSCHAFTLICHE EINRICHTUNGEN
- Labor mit Verlinkung
- ???
- ???
LEHRVERANSTALTUNGEN
- ???
- ???
- ???
PROJEKTE
- Projekt mit Verlinkung
- ???
- ???
WISSENSCHAFTLICHE MITARBEITER*INNEN

Felix Grün
Büro: 02.216 (Campus Bottrop)

Marie Schmidt
Büro: 02.216 (Campus Bottrop)

Aline Xavier Fidencio
Gastwissenschaftlerin

Muhammad Ayaz Hussain
Doktorand

Tim Sziburis
Doktorand

Farhad Rahmat
studentische Hilfskraft
RESEARCHGATE PROFIL

GOOGLE SCHOLAR PROFIL

Artikel

Schmidt, Marie Dominique; Iossifidis, Ioannis
The Spatial and Temporal Resolution of Motor Intention in Multi-Target Prediction Artikel
In: arXiv:2603.05418 [q-bio.NC], 2026.
Abstract | Links | BibTeX | Schlagwörter: BCI, Machine Learning, Motor control
@article{schmidt2026spatialtemporalresolutionmotor,
title = {The Spatial and Temporal Resolution of Motor Intention in Multi-Target Prediction},
author = {Marie Dominique Schmidt and Ioannis Iossifidis},
url = {https://arxiv.org/abs/2603.05418},
doi = {https://doi.org/10.48550/arXiv.2603.05418},
year = {2026},
date = {2026-03-05},
urldate = {2026-03-05},
journal = {arXiv:2603.05418 [q-bio.NC]},
abstract = {Reaching for grasping, and manipulating objects are essential motor functions in everyday life. Decoding human motor intentions is a central challenge for rehabilitation and assistive technologies. This study focuses on predicting intentions by inferring movement direction and target location from multichannel electromyography (EMG) signals, and investigating how spatially and temporally accurate such information can be detected relative to movement onset. We present a computational pipeline that combines data-driven temporal segmentation with classical and deep learning classifiers in order to analyse EMG data recorded during the planning, early execution, and target contact phases of a delayed reaching task.
Early intention prediction enables devices to anticipate user actions, improving responsiveness and supporting active motor recovery in adaptive rehabilitation systems. Random Forest achieves 80% accuracy and Convolutional Neural Network 75% accuracy across 25 spatial targets, each separated by 14∘ azimuth/altitude. Furthermore, a systematic evaluation of EMG channels, feature sets, and temporal windows demonstrates that motor intention can be efficiently decoded even with drastically reduced data. This work sheds light on the temporal and spatial evolution of motor intention, paving the way for anticipatory control in adaptive rehabilitation systems and driving advancements in computational approaches to motor neuroscience.},
keywords = {BCI, Machine Learning, Motor control},
pubstate = {published},
tppubtype = {article}
}
Early intention prediction enables devices to anticipate user actions, improving responsiveness and supporting active motor recovery in adaptive rehabilitation systems. Random Forest achieves 80% accuracy and Convolutional Neural Network 75% accuracy across 25 spatial targets, each separated by 14∘ azimuth/altitude. Furthermore, a systematic evaluation of EMG channels, feature sets, and temporal windows demonstrates that motor intention can be efficiently decoded even with drastically reduced data. This work sheds light on the temporal and spatial evolution of motor intention, paving the way for anticipatory control in adaptive rehabilitation systems and driving advancements in computational approaches to motor neuroscience.
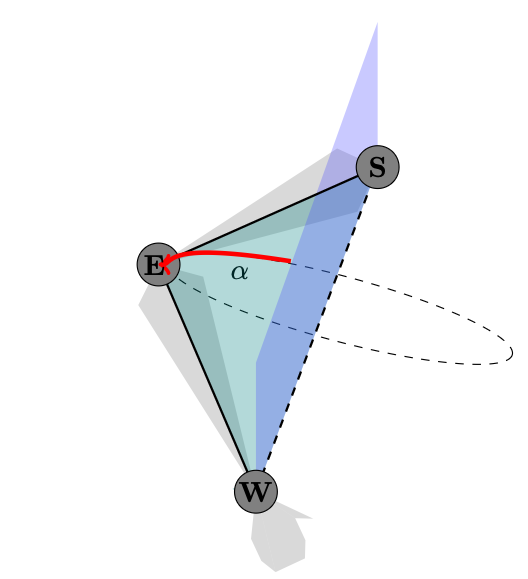
Schmidt, Marie D.; Glasmachers, Tobias; Iossifidis, Ioannis
Insights into Motor Control: Predict Muscle Activity from Upper Limb Kinematics with LSTM Networks Artikel
In: Nature Scientific Reports, 2026, ISSN: 2045-2322.
Abstract | Links | BibTeX | Schlagwörter: BCI, Computational biology and bioinformatics, Motor control, Neuroscience
@article{schmidtInsightsMotorControl2026,
title = {Insights into Motor Control: Predict Muscle Activity from Upper Limb Kinematics with LSTM Networks},
author = {Marie D. Schmidt and Tobias Glasmachers and Ioannis Iossifidis},
editor = {Nature Publishing Group},
url = {https://www.nature.com/articles/s41598-025-33696-y},
doi = {10.1038/s41598-025-33696-y},
issn = {2045-2322},
year = {2026},
date = {2026-01-05},
urldate = {2026-01-05},
journal = {Nature Scientific Reports},
publisher = {Nature Publishing Group},
abstract = {This study explores the relationship between upper limb kinematics and corresponding muscle activity, aiming to understand how predictive models can approximate motor control. We employ a Long Short-Term Memory (LSTM) network trained on kinematic end effector data to estimate muscle activity for eight muscles. The model exhibits strong predictive accuracy for new repetitions of known movements and generalizes to unseen movements, suggesting it captures underlying biomechanical principles rather than merely memorizing patterns. This generalization is particularly valuable for applications in rehabilitation and human-machine interaction, as it reduces the need for exhaustive datasets. To further investigate movement representation and learning, we analyze the impact of motion segmentation, hypothesizing that breaking movements into simpler components may improve model performance. Additionally, we explore the role of the swivel angle in reducing redundancy in arm kinematics. Another key focus is the effect of training data complexity on generalization. Specifically, we assess whether training on a diverse set of movements leads to better performance than specializing in either simple, single-joint movements or complex, multi-joint movements. The study is based on an experimental setup involving 23 distinct upper limb movements performed by five subjects. Our findings provide insights into the interplay between kinematics and muscle activity, contributing to motor control research and advancing neural network-based movement prediction.},
keywords = {BCI, Computational biology and bioinformatics, Motor control, Neuroscience},
pubstate = {published},
tppubtype = {article}
}
Saif-ur-Rehman, Muhammad; Ali, Omair; Klaes, Christian; Iossifidis, Ioannis
In: Neurocomputing, S. 131370, 2025, ISSN: 0925-2312.
Abstract | Links | BibTeX | Schlagwörter: BCI, Brain computer interface, Deep learning, Self organizing, Self-supervised machine learning, Spike Sorting
@article{saif-ur-rehmanAdaptiveSpikeDeepclassifierSelforganizing2025,
title = {Adaptive SpikeDeep-classifier: Self-organizing and Self-Supervised Machine Learning Algorithm for Online Spike Sorting},
author = {Muhammad Saif-ur-Rehman and Omair Ali and Christian Klaes and Ioannis Iossifidis},
editor = {Elsevier},
url = {https://www.sciencedirect.com/science/article/pii/S0925231225020429},
doi = {10.1016/j.neucom.2025.131370},
issn = {0925-2312},
year = {2025},
date = {2025-09-04},
urldate = {2025-09-04},
journal = {Neurocomputing},
pages = {131370},
abstract = {Objective. Invasive brain-computer interface (BCI) research is progressing towards the realization of the motor skills rehabilitation of severely disabled patients in the real world. The size of invasive micro-electrode arrays and the selection of an efficient online spike sorting algorithm (performing spike sorting at run time) are two key factors that play pivotal roles in the successful decoding of the user’s intentions. The process of spike sorting includes the selection of channels that record the spike activity (SA) and determines the SA of different sources (neurons), on selected channels individually. The neural data recorded with dense micro-electrode arrays is time-varying and often contaminated with non-stationary noise. Unfortunately, current state-of-the-art spike sorting algorithms are incapable of handling the massively increasing amount of time-varying data resulting from the dense microelectrode arrays, which makes the spike sorting one of the fragile components of the online BCI decoding framework. Approach. This study proposed an adaptive and self-organized algorithm for online spike sorting, named as Adaptive SpikeDeep-Classifier (Ada-SpikeDeepClassifier). Our algorithm uses SpikeDeeptector for the channel selection, an adaptive background activity rejector (Ada-BAR) for discarding the background events, and an adaptive spike deep-classifier (Ada-SpikeDeepClassifier) for classifying the SA of different neural units. The process of spike sorting is accomplished by concatenating SpikeDeeptector, Ada-BAR and Ada-SpikeDeepclassifier. Results. The proposed algorithm is evaluated on two different categories of data: a human data-set recorded in our lab, and a publicly available simulated data-set to avoid subjective biases and labeling errors. The proposed Ada-SpikeDeepClassifier outperformed our previously published SpikeDeep-Classifier and eight conventional spike sorting algorithms and produce comparable results to state of the art deep learning based algorithms. Significance. To the best of our knowledge, the proposed algorithm is the first spike sorting algorithm that autonomously adapts to the shift in the distribution of noise and SA data and perform spike sorting without human interventions in various kinds of experimental settings. In addition, the proposed algorithm builds upon artificial neural networks, which makes it an ideal candidate for being embedded on neuromorphic chips that are also suitable for wearable invasive BCI.},
keywords = {BCI, Brain computer interface, Deep learning, Self organizing, Self-supervised machine learning, Spike Sorting},
pubstate = {published},
tppubtype = {article}
}
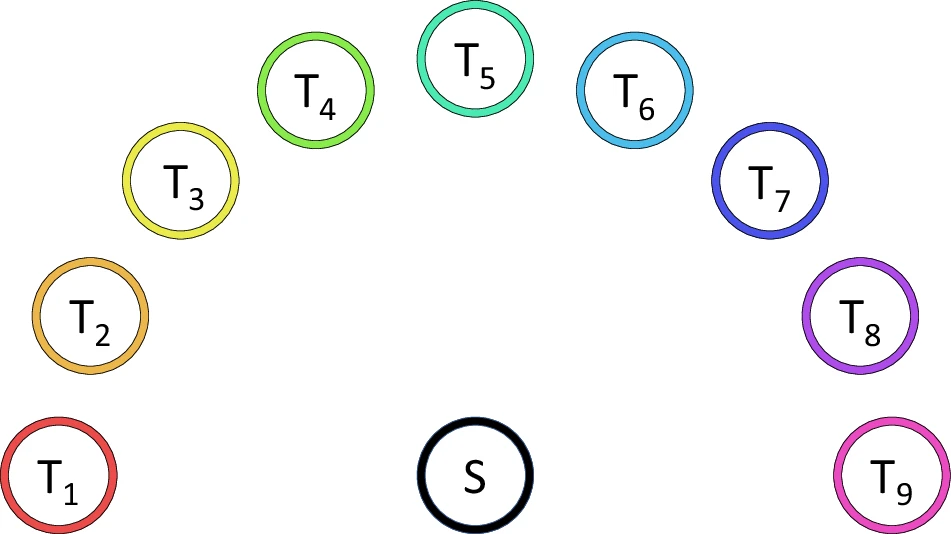
Sziburis, Tim; Blex, Susanne; Glasmachers, Tobias; Iossifidis, Ioannis
Hand Motion Catalog of Human Center-Out Transport Trajectories Measured Redundantly in 3D Task-Space Artikel
In: Bd. 12, Nr. 1, S. 1293, 2025, ISSN: 2052-4463.
Abstract | Links | BibTeX | Schlagwörter: BCI, Biomedical engineering, Motor control, Physiology
@article{sziburisHandMotionCatalog2025,
title = {Hand Motion Catalog of Human Center-Out Transport Trajectories Measured Redundantly in 3D Task-Space},
author = {Tim Sziburis and Susanne Blex and Tobias Glasmachers and Ioannis Iossifidis},
editor = {Nature},
url = {https://www.nature.com/articles/s41597-025-05576-7},
doi = {10.1038/s41597-025-05576-7},
issn = {2052-4463},
year = {2025},
date = {2025-07-24},
urldate = {2025-07-24},
volume = {12},
number = {1},
pages = {1293},
publisher = {Nature Publishing Group},
abstract = {Motion modeling and variability analysis bear the potential to identify movement pathology but require profound data. We introduce a systematic dataset of 3D center-out task-space trajectories of human hand transport movements in a standardized setting. This set-up is characterized by reproducibility, leading to reliable transferability to various locations. The transport tasks consist of grasping a cylindrical object from a unified start position and transporting it to one of nine target locations in unconstrained operational space. The measurement procedure is automatized to record ten trials per target location and participant. The dataset comprises 90 movement trajectories for each hand of 31 participants without known movement disorders (21 to 78 years), resulting in 5580 trials. In addition, handedness is determined using the EHI. Data are recorded redundantly and synchronously by an optical tracking system and a single IMU sensor. Unlike the stationary capturing system, the IMU can be considered a portable, low-cost, and energy-efficient alternative to be implemented on embedded systems, for example in medical evaluation scenarios.},
keywords = {BCI, Biomedical engineering, Motor control, Physiology},
pubstate = {published},
tppubtype = {article}
}
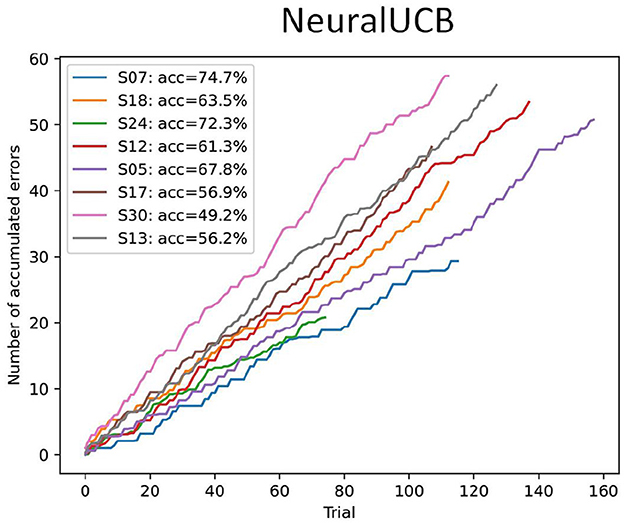
Fidêncio, Aline Xavier; Grün, Felix; Klaes, Christian; Iossifidis, Ioannis
Hybrid Brain-Computer Interface Using Error-Related Potential and Reinforcement Learning Artikel
In: Frontiers in Human Neuroscience, Bd. 19, 2025, ISSN: 1662-5161.
Abstract | Links | BibTeX | Schlagwörter: adaptive brain-computer interface, BCI, EEG, error-related potentials (ErrPs), Machine Learning, motor imagery (MI), reinforcement learning (RL)
@article{xavierfidencioHybridBraincomputerInterface2025,
title = {Hybrid Brain-Computer Interface Using Error-Related Potential and Reinforcement Learning},
author = {Aline Xavier Fidêncio and Felix Grün and Christian Klaes and Ioannis Iossifidis},
editor = {Frontiers},
url = {https://www.frontiersin.org/journals/human-neuroscience/articles/10.3389/fnhum.2025.1569411/full},
doi = {10.3389/fnhum.2025.1569411},
issn = {1662-5161},
year = {2025},
date = {2025-06-04},
urldate = {2025-06-04},
journal = {Frontiers in Human Neuroscience},
volume = {19},
publisher = {Frontiers},
abstract = {Brain-computer interfaces (BCIs) offer alternative communication methods for individuals with motor disabilities, aiming to improve their quality of life through external device control. However, non-invasive BCIs using electroencephalography (EEG) often suffer from performance limitations due to non-stationarities arising from changes in mental state or device characteristics. Addressing these challenges motivates the development of adaptive systems capable of real-time adjustment. This study investigates a novel approach for creating an adaptive, error-related potential (ErrP)-based BCI using reinforcement learning (RL) to dynamically adapt to EEG signal variations. The framework was validated through experiments on a publicly available motor imagery dataset and a novel fast-paced protocol designed to enhance user engagement. Results showed that RL agents effectively learned control policies from user interactions, maintaining robust performance across datasets. However, findings from the game-based protocol revealed that fast-paced motor imagery tasks were ineffective for most participants, highlighting critical challenges in real-time BCI task design. Overall, the results demonstrate the potential of RL for enhancing BCI adaptability while identifying practical constraints in task complexity and user responsiveness.},
keywords = {adaptive brain-computer interface, BCI, EEG, error-related potentials (ErrPs), Machine Learning, motor imagery (MI), reinforcement learning (RL)},
pubstate = {published},
tppubtype = {article}
}
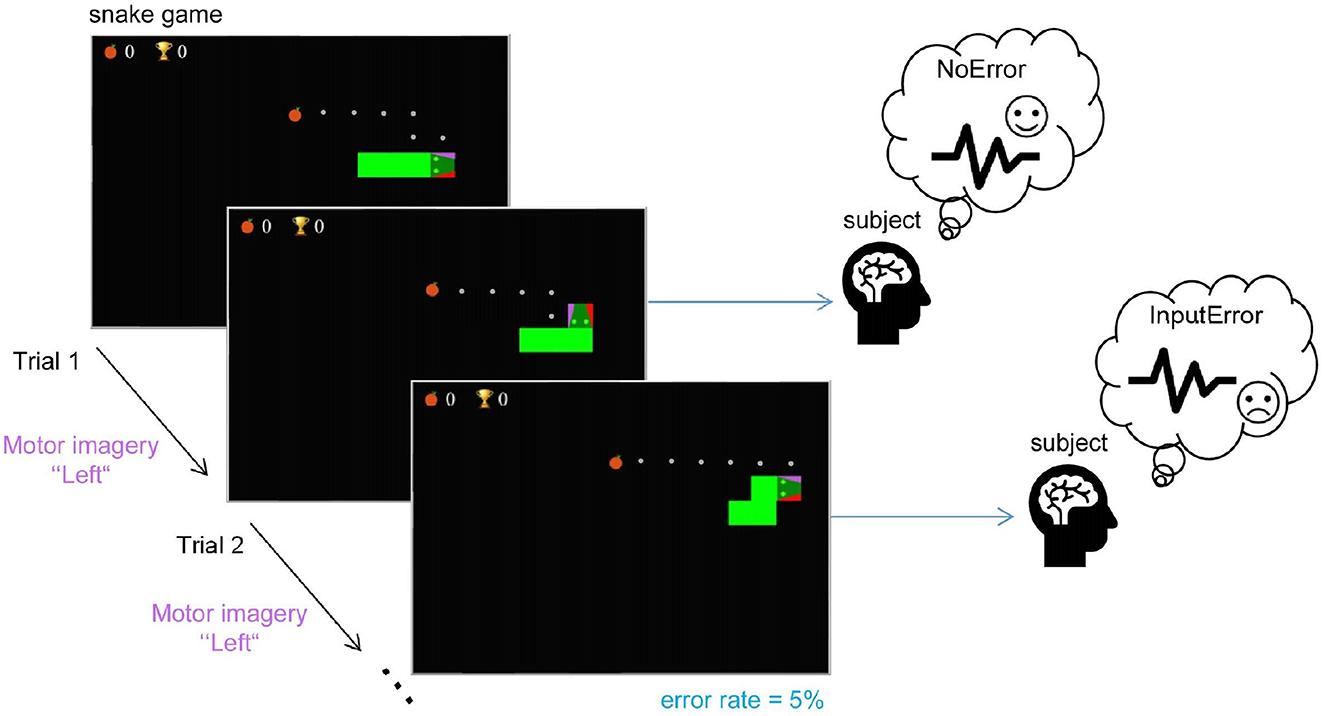
Fidêncio, Aline Xavier; Grün, Felix; Klaes, Christian; Iossifidis, Ioannis
Error-Related Potential Driven Reinforcement Learning for Adaptive Brain-Computer Interfaces Artikel
In: Arxiv, 2025.
Abstract | Links | BibTeX | Schlagwörter: BCI, Computer Science - Human-Computer Interaction, Computer Science - Machine Learning, EEG, Quantitative Biology - Neurons and Cognition, Reinforcement learning
@article{fidencioErrorrelatedPotentialDriven2025,
title = {Error-Related Potential Driven Reinforcement Learning for Adaptive Brain-Computer Interfaces},
author = {Aline Xavier Fidêncio and Felix Grün and Christian Klaes and Ioannis Iossifidis},
url = {http://arxiv.org/abs/2502.18594},
doi = {10.48550/arXiv.2502.18594},
year = {2025},
date = {2025-02-25},
urldate = {2025-02-25},
journal = {Arxiv},
abstract = {Brain-computer interfaces (BCIs) provide alternative communication methods for individuals with motor disabilities by allowing control and interaction with external devices. Non-invasive BCIs, especially those using electroencephalography (EEG), are practical and safe for various applications. However, their performance is often hindered by EEG non-stationarities, caused by changing mental states or device characteristics like electrode impedance. This challenge has spurred research into adaptive BCIs that can handle such variations. In recent years, interest has grown in using error-related potentials (ErrPs) to enhance BCI performance. ErrPs, neural responses to errors, can be detected non-invasively and have been integrated into different BCI paradigms to improve performance through error correction or adaptation. This research introduces a novel adaptive ErrP-based BCI approach using reinforcement learning (RL). We demonstrate the feasibility of an RL-driven adaptive framework incorporating ErrPs and motor imagery. Utilizing two RL agents, the framework adapts dynamically to EEG non-stationarities. Validation was conducted using a publicly available motor imagery dataset and a fast-paced game designed to boost user engagement. Results show the framework's promise, with RL agents learning control policies from user interactions and achieving robust performance across datasets. However, a critical insight from the game-based protocol revealed that motor imagery in a high-speed interaction paradigm was largely ineffective for participants, highlighting task design limitations in real-time BCI applications. These findings underscore the potential of RL for adaptive BCIs while pointing out practical constraints related to task complexity and user responsiveness.},
keywords = {BCI, Computer Science - Human-Computer Interaction, Computer Science - Machine Learning, EEG, Quantitative Biology - Neurons and Cognition, Reinforcement learning},
pubstate = {published},
tppubtype = {article}
}
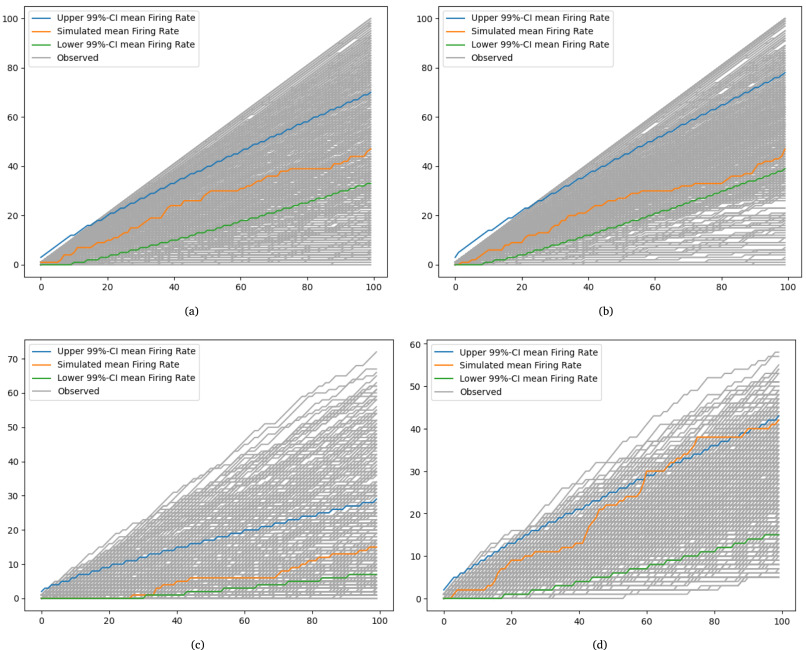
Lehmler, Stephan Johann; Saif-ur-Rehman, Muhammad; Glasmachers, Tobias; Iossifidis, Ioannis
In: Neurocomputing, S. 128473, 2024, ISSN: 0925-2312.
Abstract | Links | BibTeX | Schlagwörter: Artificial neural networks, Generalization, Machine Learning, Memorization, Poisson process, Stochastic modeling
@article{lehmlerUnderstandingActivationPatterns2024,
title = {Understanding Activation Patterns in Artificial Neural Networks by Exploring Stochastic Processes: Discriminating Generalization from Memorization},
author = {Stephan Johann Lehmler and Muhammad Saif-ur-Rehman and Tobias Glasmachers and Ioannis Iossifidis},
editor = {Elsevier},
url = {https://www.sciencedirect.com/science/article/pii/S092523122401244X},
doi = {10.1016/j.neucom.2024.128473},
issn = {0925-2312},
year = {2024},
date = {2024-09-19},
urldate = {2024-09-19},
journal = {Neurocomputing},
pages = {128473},
abstract = {To gain a deeper understanding of the behavior and learning dynamics of artificial neural networks, mathematical abstractions and models are valuable. They provide a simplified perspective and facilitate systematic investigations. In this paper, we propose to analyze dynamics of artificial neural activation using stochastic processes, which have not been utilized for this purpose thus far. Our approach involves modeling the activation patterns of nodes in artificial neural networks as stochastic processes. By focusing on the activation frequency, we can leverage techniques used in neuroscience to study neural spike trains. Specifically, we extract the activity of individual artificial neurons during a classification task and model their activation frequency. The underlying process model is an arrival process following a Poisson distribution.We examine the theoretical fit of the observed data generated by various artificial neural networks in image recognition tasks to the proposed model’s key assumptions. Through the stochastic process model, we derive measures describing activation patterns of each network. We analyze randomly initialized, generalizing, and memorizing networks, allowing us to identify consistent differences in learning methods across multiple architectures and training sets. We calculate features describing the distribution of Activation Rate and Fano Factor, which prove to be stable indicators of memorization during learning. These calculated features offer valuable insights into network behavior. The proposed model demonstrates promising results in describing activation patterns and could serve as a general framework for future investigations. It has potential applications in theoretical simulation studies as well as practical areas such as pruning or transfer learning.},
keywords = {Artificial neural networks, Generalization, Machine Learning, Memorization, Poisson process, Stochastic modeling},
pubstate = {published},
tppubtype = {article}
}
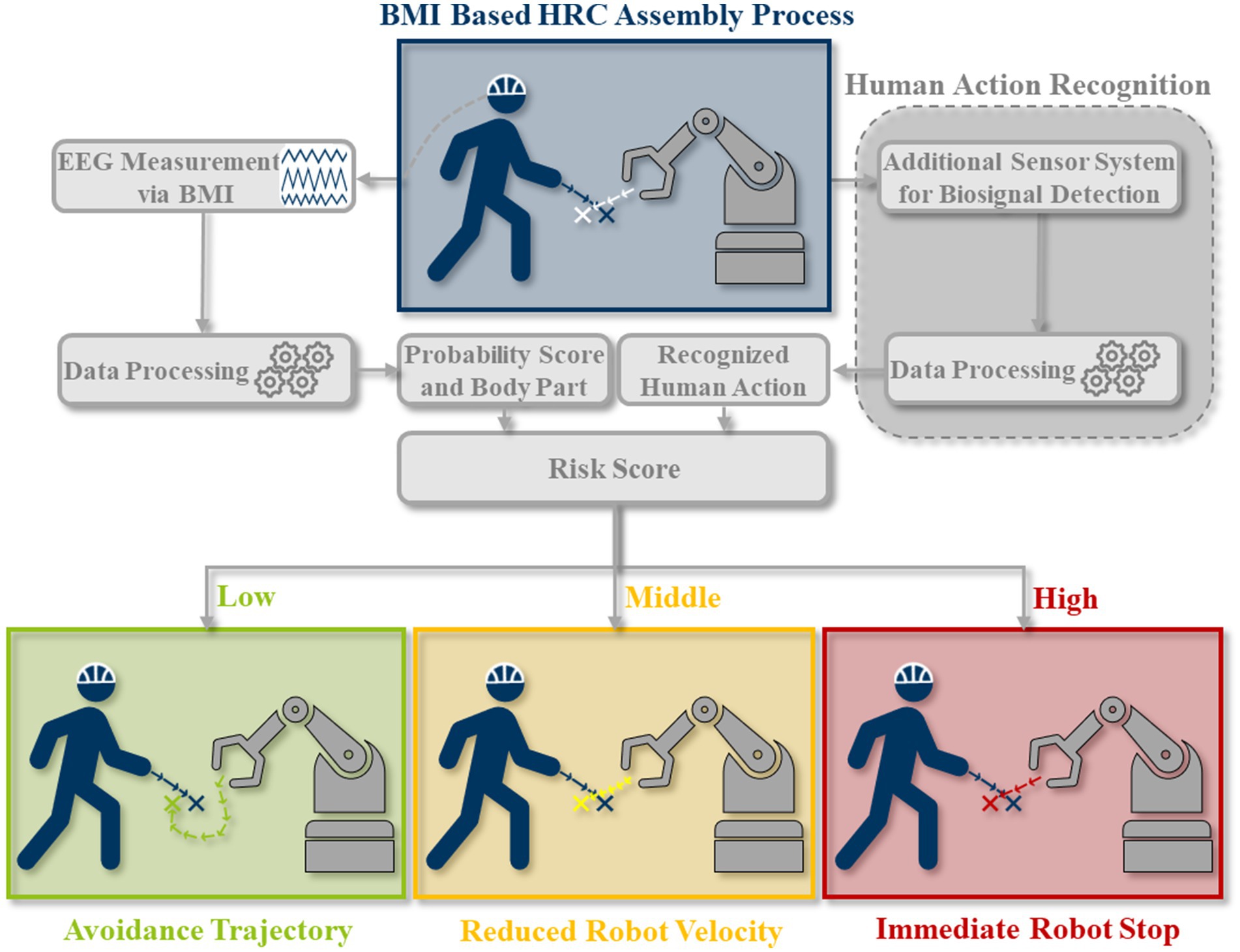
Pilacinski, Artur; Christ, Lukas; Boshoff, Marius; Iossifidis, Ioannis; Adler, Patrick; Miro, Michael; Kuhlenkötter, Bernd; Klaes, Christian
In: Frontiers in Neurorobotics, Bd. 18, 2024, ISSN: 1662-5218.
Links | BibTeX | Schlagwörter: BCI, EEG, Human action recognition, human-robot collaboration, Sensor Fusion
@article{pilacinskiHumanCollaborativeLoop2024,
title = {Human in the Collaborative Loop: A Strategy for Integrating Human Activity Recognition and Non-Invasive Brain-Machine Interfaces to Control Collaborative Robots},
author = {Artur Pilacinski and Lukas Christ and Marius Boshoff and Ioannis Iossifidis and Patrick Adler and Michael Miro and Bernd Kuhlenkötter and Christian Klaes},
url = {https://www.frontiersin.org/journals/neurorobotics/articles/10.3389/fnbot.2024.1383089/full},
doi = {10.3389/fnbot.2024.1383089},
issn = {1662-5218},
year = {2024},
date = {2024-09-18},
urldate = {2024-09-18},
journal = {Frontiers in Neurorobotics},
volume = {18},
publisher = {Frontiers},
keywords = {BCI, EEG, Human action recognition, human-robot collaboration, Sensor Fusion},
pubstate = {published},
tppubtype = {article}
}
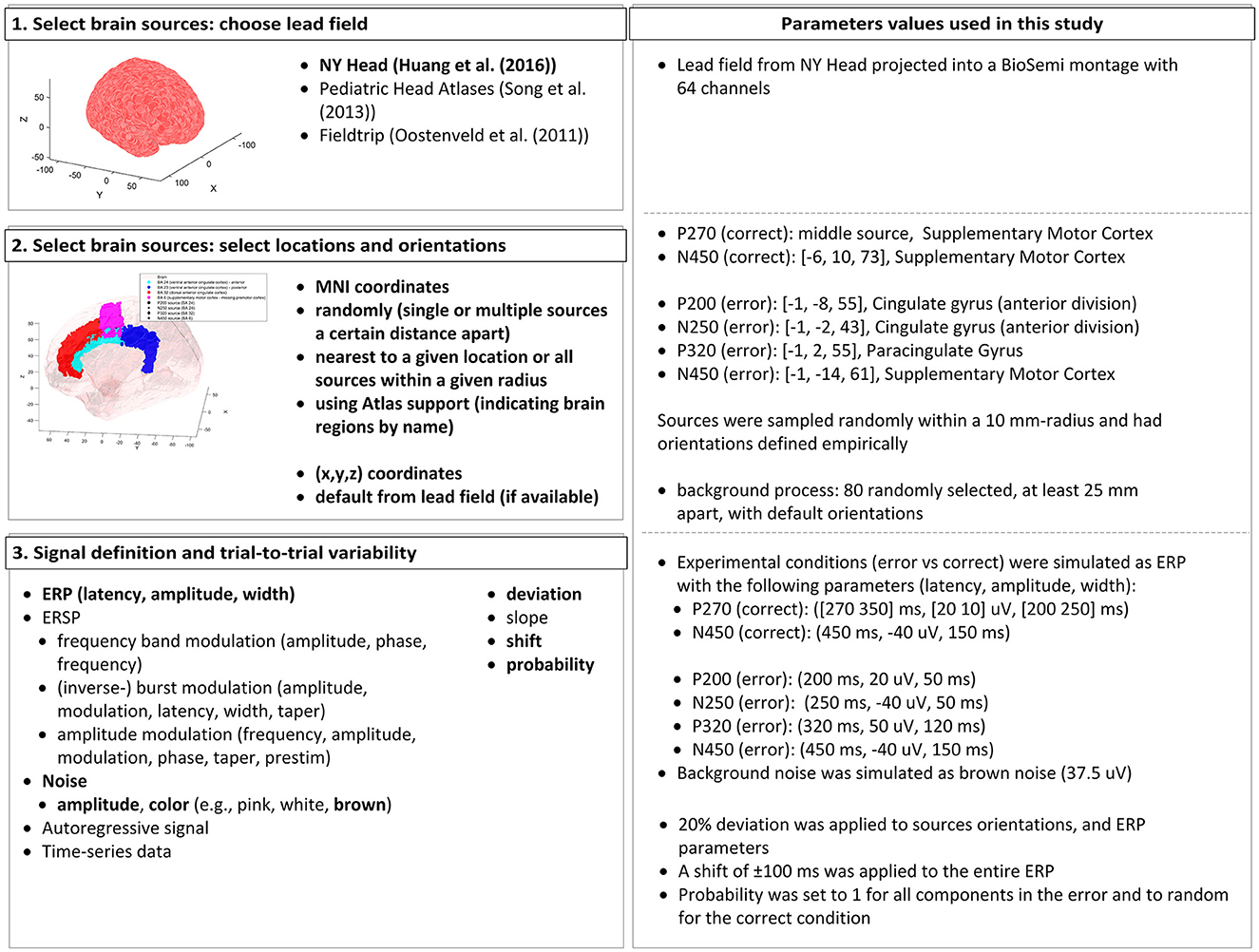
Fidêncio, Aline Xavier; Klaes, Christian; Iossifidis, Ioannis
A Generic Error-Related Potential Classifier Based on Simulated Subjects Artikel
In: Frontiers in Human Neuroscience, Bd. 18, S. 1390714, 2024, ISSN: 1662-5161.
Abstract | Links | BibTeX | Schlagwörter: adaptive brain-machine (computer) interface, BCI, EEG, Error-related potential (ErrP), ErrP classifier, Generic decoder, Machine Learning, SEREEGA, Simulation
@article{xavierfidencioGenericErrorrelatedPotential2024,
title = {A Generic Error-Related Potential Classifier Based on Simulated Subjects},
author = {Aline Xavier Fidêncio and Christian Klaes and Ioannis Iossifidis},
editor = {Frontiers Media SA},
url = {https://www.frontiersin.org/journals/human-neuroscience/articles/10.3389/fnhum.2024.1390714/full},
doi = {10.3389/fnhum.2024.1390714},
issn = {1662-5161},
year = {2024},
date = {2024-07-19},
urldate = {2024-07-19},
journal = {Frontiers in Human Neuroscience},
volume = {18},
pages = {1390714},
publisher = {Frontiers},
abstract = {$<$p$>$Error-related potentials (ErrPs) are brain signals known to be generated as a reaction to erroneous events. Several works have shown that not only self-made errors but also mistakes generated by external agents can elicit such event-related potentials. The possibility of reliably measuring ErrPs through non-invasive techniques has increased the interest in the brain-computer interface (BCI) community in using such signals to improve performance, for example, by performing error correction. Extensive calibration sessions are typically necessary to gather sufficient trials for training subject-specific ErrP classifiers. This procedure is not only time-consuming but also boresome for participants. In this paper, we explore the effectiveness of ErrPs in closed-loop systems, emphasizing their dependency on precise single-trial classification. To guarantee the presence of an ErrPs signal in the data we employ and to ensure that the parameters defining ErrPs are systematically varied, we utilize the open-source toolbox SEREEGA for data simulation. We generated training instances and evaluated the performance of the generic classifier on both simulated and real-world datasets, proposing a promising alternative to conventional calibration techniques. Results show that a generic support vector machine classifier reaches balanced accuracies of 72.9%, 62.7%, 71.0%, and 70.8% on each validation dataset. While performing similarly to a leave-one-subject-out approach for error class detection, the proposed classifier shows promising generalization across different datasets and subjects without further adaptation. Moreover, by utilizing SEREEGA, we can systematically adjust parameters to accommodate the variability in the ErrP, facilitating the systematic validation of closed-loop setups. Furthermore, our objective is to develop a universal ErrP classifier that captures the signal's variability, enabling it to determine the presence or absence of an ErrP in real EEG data.$<$/p$>$},
keywords = {adaptive brain-machine (computer) interface, BCI, EEG, Error-related potential (ErrP), ErrP classifier, Generic decoder, Machine Learning, SEREEGA, Simulation},
pubstate = {published},
tppubtype = {article}
}
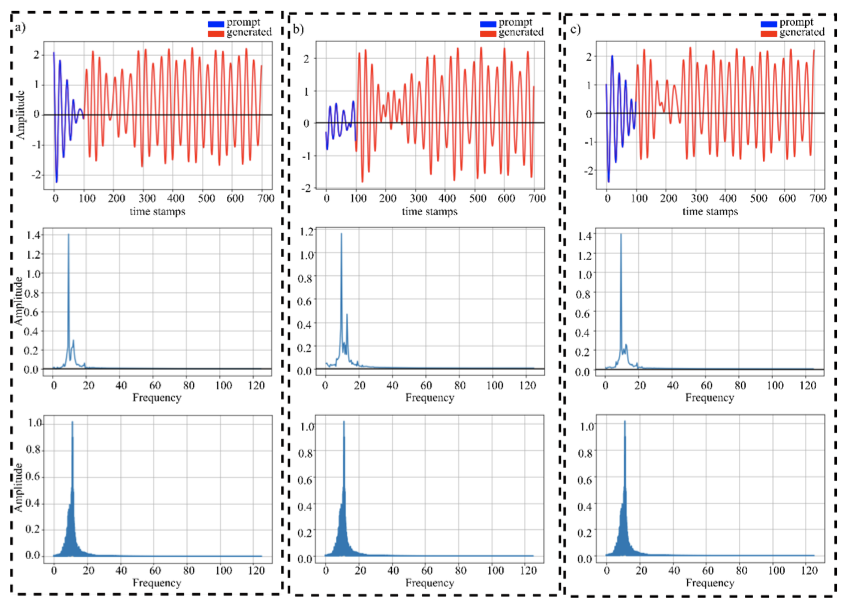
Ali, Omair; Saif-ur-Rehman, Muhammad; Metzler, Marita; Glasmachers, Tobias; Iossifidis, Ioannis; Klaes, Christian
GET: A Generative EEG Transformer for Continuous Context-Based Neural Signals Artikel
In: arXiv:2406.03115 [q-bio], 2024.
Abstract | Links | BibTeX | Schlagwörter: BCI, EEG, Machine Learning, Quantitative Biology - Neurons and Cognition
@article{aliGETGenerativeEEG2024,
title = {GET: A Generative EEG Transformer for Continuous Context-Based Neural Signals},
author = {Omair Ali and Muhammad Saif-ur-Rehman and Marita Metzler and Tobias Glasmachers and Ioannis Iossifidis and Christian Klaes},
url = {http://arxiv.org/abs/2406.03115},
doi = {10.48550/arXiv.2406.03115},
year = {2024},
date = {2024-06-09},
urldate = {2024-06-09},
journal = {arXiv:2406.03115 [q-bio]},
abstract = {Generating continuous electroencephalography (EEG) signals through advanced artificial neural networks presents a novel opportunity to enhance brain-computer interface (BCI) technology. This capability has the potential to significantly enhance applications ranging from simulating dynamic brain activity and data augmentation to improving real-time epilepsy detection and BCI inference. By harnessing generative transformer neural networks, specifically designed for EEG signal generation, we can revolutionize the interpretation and interaction with neural data. Generative AI has demonstrated significant success across various domains, from natural language processing (NLP) and computer vision to content creation in visual arts and music. It distinguishes itself by using large-scale datasets to construct context windows during pre-training, a technique that has proven particularly effective in NLP, where models are fine-tuned for specific downstream tasks after extensive foundational training. However, the application of generative AI in the field of BCIs, particularly through the development of continuous, context-rich neural signal generators, has been limited. To address this, we introduce the Generative EEG Transformer (GET), a model leveraging transformer architecture tailored for EEG data. The GET model is pre-trained on diverse EEG datasets, including motor imagery and alpha wave datasets, enabling it to produce high-fidelity neural signals that maintain contextual integrity. Our empirical findings indicate that GET not only faithfully reproduces the frequency spectrum of the training data and input prompts but also robustly generates continuous neural signals. By adopting the successful training strategies of the NLP domain for BCIs, the GET sets a new standard for the development and application of neural signal generation technologies.},
keywords = {BCI, EEG, Machine Learning, Quantitative Biology - Neurons and Cognition},
pubstate = {published},
tppubtype = {article}
}